PageRank
History
PageRank was developed at Stanford University by Larry Page (hence the name Page-Rank[3]) and later Sergey Brin as part of a research project about a new kind of search engine. The project started in 1995 and led to a functional prototype, named Google, in 1998. Shortly after, Page and Brin founded Google Inc., the company behind the Google search engine. While just one of many factors which determine the ranking of Google search results, PageRank continues to provide the basis for all of Google’s web search tools.[1]
PageRank is based on citation analysis that was developed in the 1950s by Eugene Garfield at the University of Pennsylvania. Google’s founders cite Garfield’s work in their original paper. In this way virtual communities of webpages are found. Teoma’s search technology uses a communities approach in its ranking algorithm. NEC Research Institute has worked on similar technology. Web link analysis was first developed by Jon Kleinberg and his team while working on the CLEVER project at IBM’s Almaden Research Center.
Algorithm
PageRank is a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page. PageRank can be calculated for any-size collection of documents. It is assumed in several research papers that the distribution is evenly divided between all documents in the collection at the beginning of the computational process. The PageRank computations require several passes, called “iterations”, through the collection to adjust approximate PageRank values to more closely reflect the theoretical true value.
A probability is expressed as a numeric value between 0 and 1. A 0.5 probability is commonly expressed as a “50% chance” of something happening. Hence, a PageRank of 0.5 means there is a 50% chance that a person clicking on a random link will be directed to the document with the 0.5 PageRank.
Simplified algorithm

How PageRank Works
Assume a small universe of four web pages: A, B, C and D. The initial approximation of PageRank would be evenly divided between these four documents. Hence, each document would begin with an estimated PageRank of 0.25.
In the original form of PageRank initial values were simply 1. This meant that the sum of all pages was the total number of pages on the web. Later versions of PageRank (see the below formulas) would assume a probability distribution between 0 and 1. Here we’re going to simply use a probability distribution hence the initial value of 0.25.
If pages B, C, and D each only link to A, they would each confer 0.25 PageRank to A. All PageRank PR( ) in this simplistic system would thus gather to A because all links would be pointing to A.

But then suppose page B also has a link to page C, and page D has links to all three pages. The value of the link-votes is divided among all the outbound links on a page. Thus, page B gives a vote worth 0.125 to page A and a vote worth 0.125 to page C. Only one third of D‘s PageRank is counted for A’s PageRank (approximately 0.083).
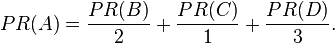
In other words, the PageRank conferred by an outbound link L( ) is equal to the document’s own PageRank score divided by the normalized number of outbound links (it is assumed that links to specific URLs only count once per document).

In the general case, the PageRank value for any page u can be expressed as:
 ,
,
i.e. the PageRank value for a page u is dependent on the PageRank values for each page v out of the set Bu (this set contains all pages linking to page u), divided by the number L(v) of links from page v.
Damping factor
The PageRank theory holds that even an imaginary surfer who is randomly clicking on links will eventually stop clicking. The probability, at any step, that the person will continue is a damping factor d. Various studies have tested different damping factors, but it is generally assumed that the damping factor will be set around 0.85.[4]
The damping factor is subtracted from 1 (and in some variations of the algorithm, the result is divided by the number of documents in the collection) and this term is then added to the product of the damping factor and the sum of the incoming PageRank scores.
That is,

or (N = the number of documents in collection)

So any page’s PageRank is derived in large part from the PageRanks of other pages. The damping factor adjusts the derived value downward. The second formula above supports the original statement in Page and Brin’s paper that “the sum of all PageRanks is one”.[2] Unfortunately, however, Page and Brin gave the first formula, which has led to some confusion.
Google recalculates PageRank scores each time it crawls the Web and rebuilds its index. As Google increases the number of documents in its collection, the initial approximation of PageRank decreases for all documents.
The formula uses a model of a random surfer who gets bored after several clicks and switches to a random page. The PageRank value of a page reflects the chance that the random surfer will land on that page by clicking on a link. It can be understood as a Markov chain in which the states are pages, and the transitions are all equally probable and are the links between pages.
If a page has no links to other pages, it becomes a sink and therefore terminates the random surfing process. However, the solution is quite simple. If the random surfer arrives at a sink page, it picks another URL at random and continues surfing again.
When calculating PageRank, pages with no outbound links are assumed to link out to all other pages in the collection. Their PageRank scores are therefore divided evenly among all other pages. In other words, to be fair with pages that are not sinks, these random transitions are added to all nodes in the Web, with a residual probability of usually d = 0.85, estimated from the frequency that an average surfer uses his or her browser’s bookmark feature.
So, the equation is as follows:

where p1,p2,…,pN are the pages under consideration, M(pi) is the set of pages that link to pi, L(pj) is the number of outbound links on page pj, and N is the total number of pages.
The PageRank values are the entries of the dominant eigenvector of the modified adjacency matrix. This makes PageRank a particularly elegant metric: the eigenvector is
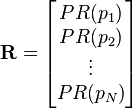
where R is the solution of the equation
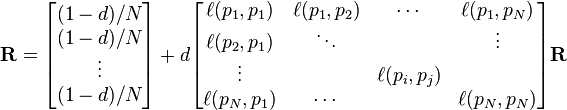
where the adjacency function 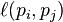 is 0 if page pj does not link to pi, and normalised such that, for each j
is 0 if page pj does not link to pi, and normalised such that, for each j
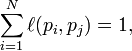
i.e. the elements of each column sum up to 1.
This is a variant of the eigenvector centrality measure used commonly in network analysis.
The values of the PageRank eigenvector are fast to approximate (only a few iterations are needed) and in practice it gives good results.
As a result of Markov theory, it can be shown that the PageRank of a page is the probability of being at that page after lots of clicks. This happens to equal t − 1 where t is the expectation of the number of clicks (or random jumps) required to get from the page back to itself.
The main disadvantage is that it favors older pages, because a new page, even a very good one, will not have many links unless it is part of an existing site (a site being a densely connected set of pages, such as Wikipedia). The Google Directory (itself a derivative of the Open Directory Project) allows users to see results sorted by PageRank within categories. The Google Directory is the only service offered by Google where PageRank directly determines display order. In Google’s other search services (such as its primary Web search) PageRank is used to weight the relevance scores of pages shown in search results.
Several strategies have been proposed to accelerate the computation of PageRank.[5]
Various strategies to manipulate PageRank have been employed in concerted efforts to improve search results rankings and monetize advertising links. These strategies have severely impacted the reliability of the PageRank concept, which seeks to determine which documents are actually highly valued by the Web community.
Google is known to actively penalize link farms and other schemes designed to artificially inflate PageRank. In December 2007 Google started actively penalizing sites selling paid text links. How Google identifies link farms and other PageRank manipulation tools are among Google’s trade secrets.
source: Wikipedia.http://en.wikipedia.org/wiki/PageRank